GPU高速平行運算
GPU與CPU同為現今個人電腦、筆記型電腦、伺服器乃至超級電腦的標準配備,藉由在硬體設計上提供大量算術邏輯單元(Arithmetic Logic Unit, ALU)以滿足影像處理所需計算密集(compute- intensive)與高度平行計算(highly parallel computation)需求。由於無論是簡易或複雜的演算法最終仍須透過基礎四則運算方可利用電腦求得解析解或者近似值,與影像處理所需運算方式無異,圖形處理器獨立製造商NVIDIA為此於民國96年提出Compute Unified Device Architecture(CUDA)整合技術,使得使用者得以應用旗下量產之GPU滿足高速平行計算應用需求。本公司團隊已利用GPU高速平行運算開發出GPU化NewC河川模式、GPU化NeSIM淹水模式、GPU化LBM二維淺水波模式以及GPU化克利金法雨量內插模式。
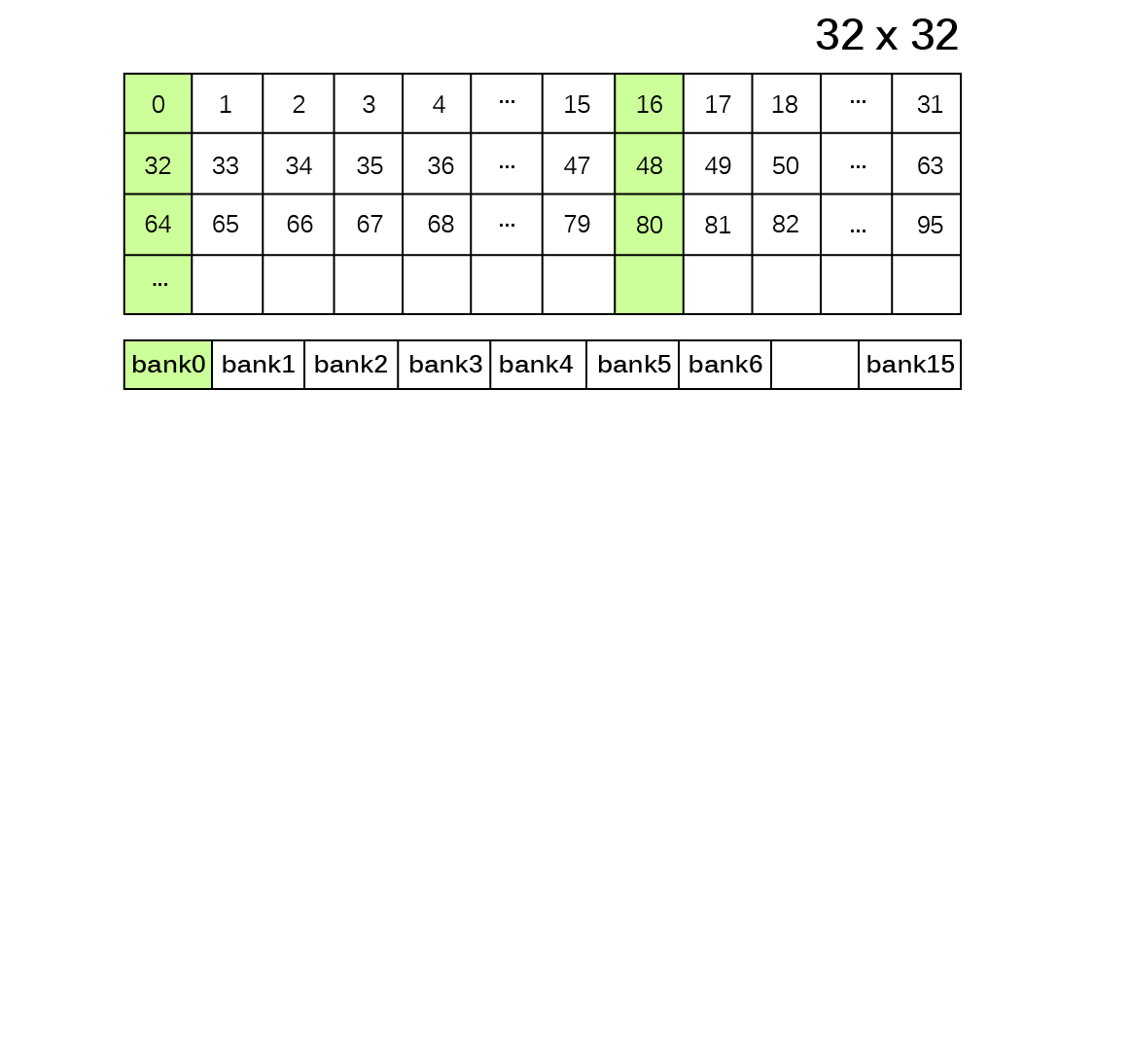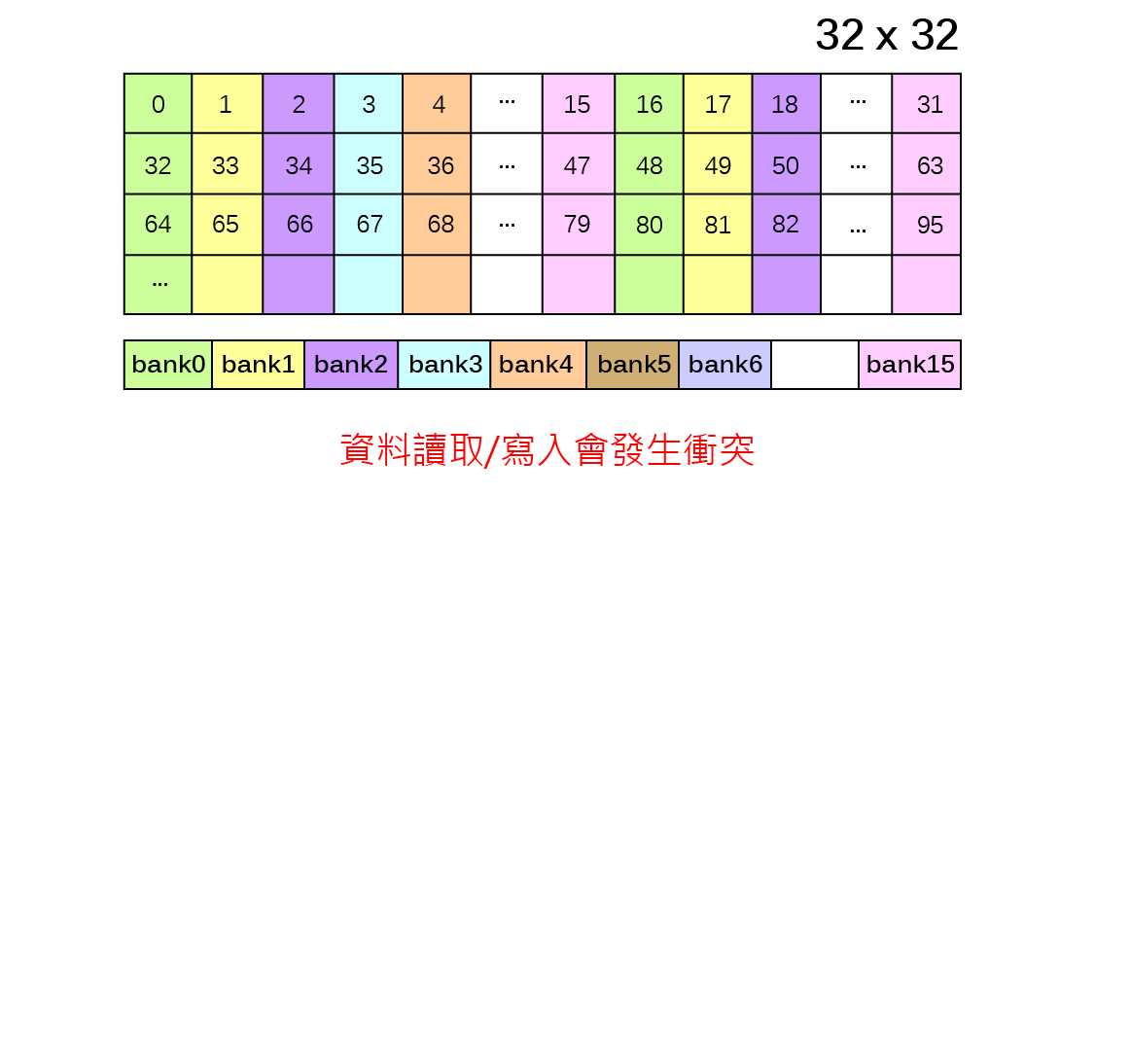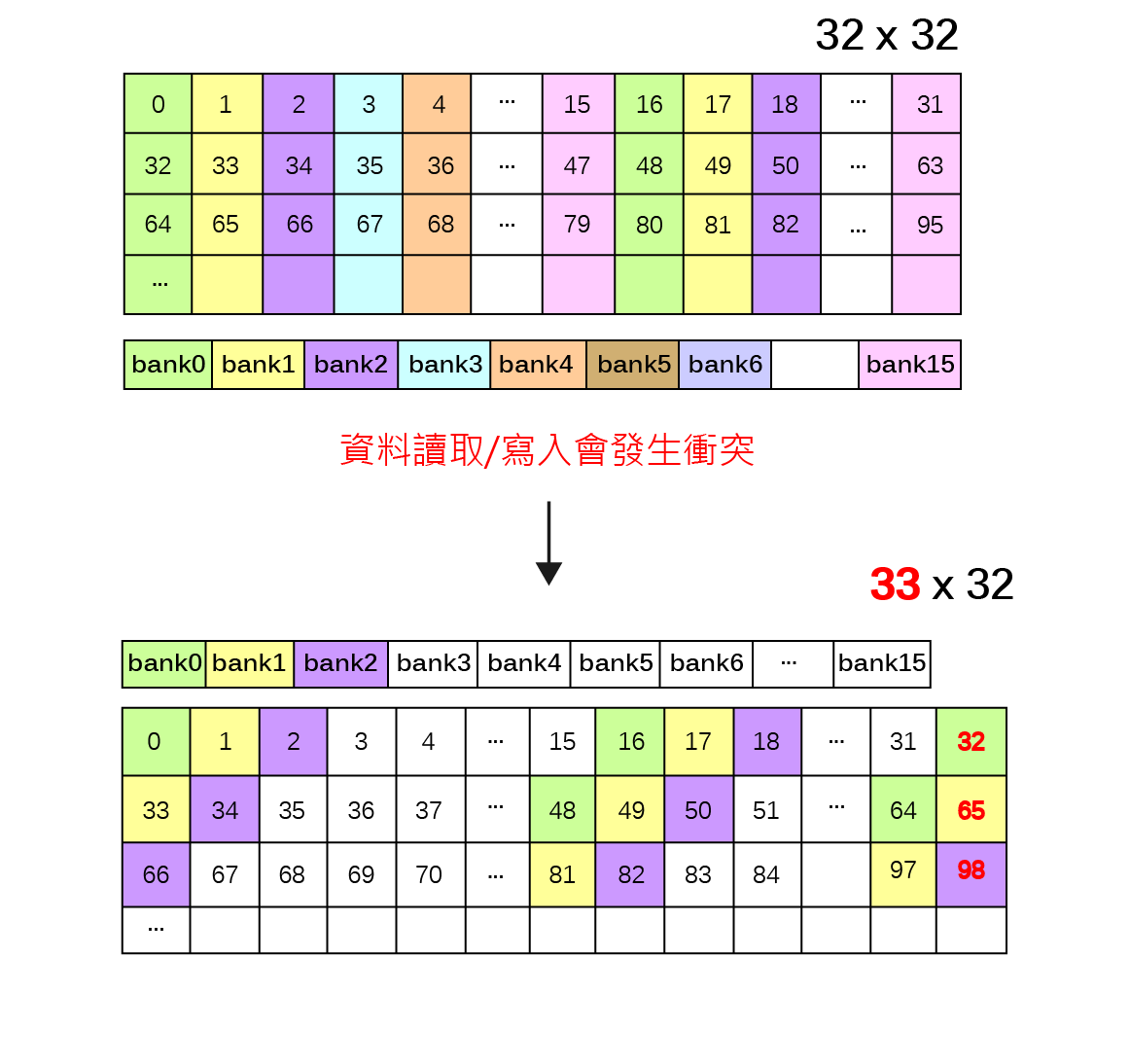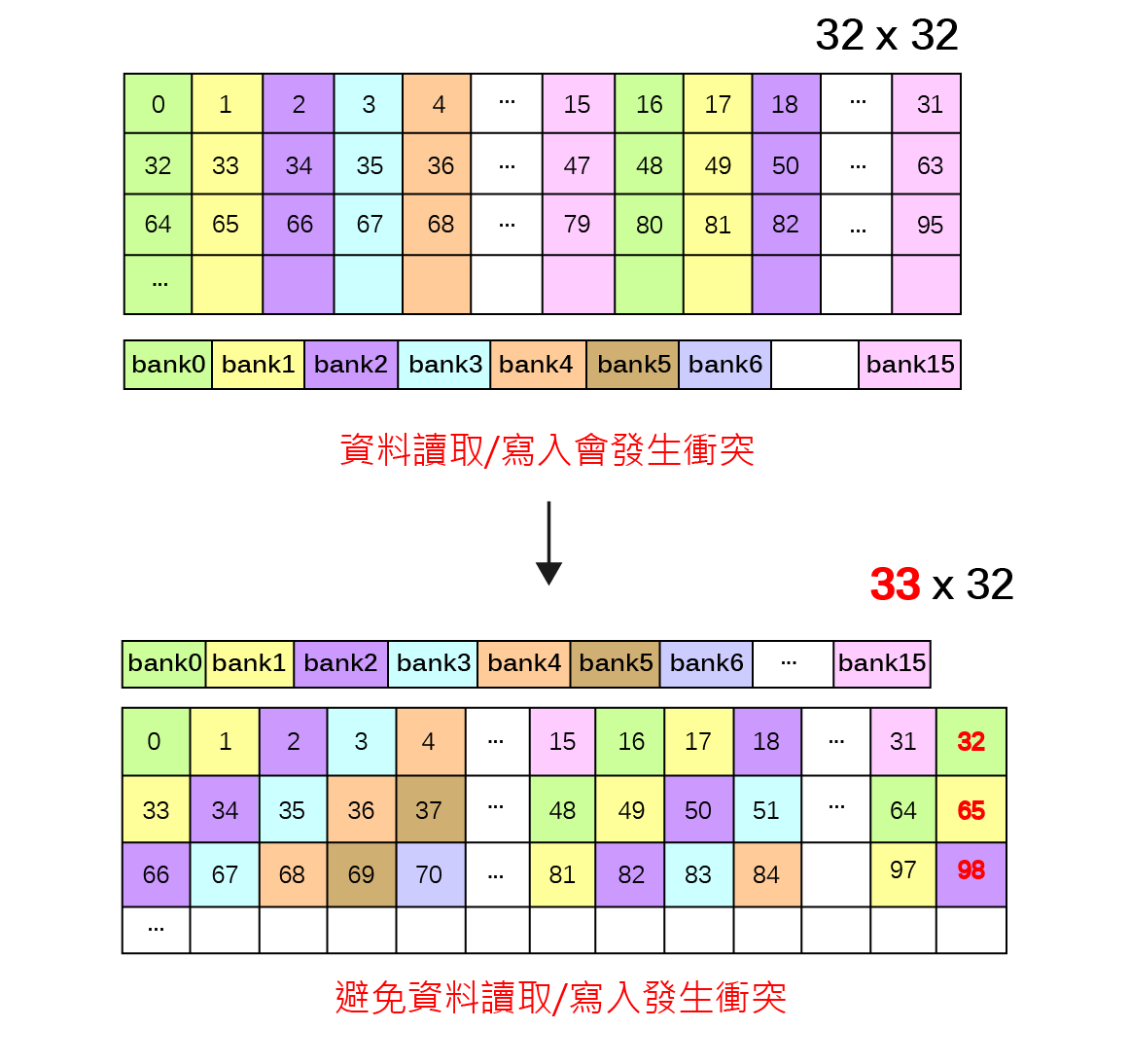
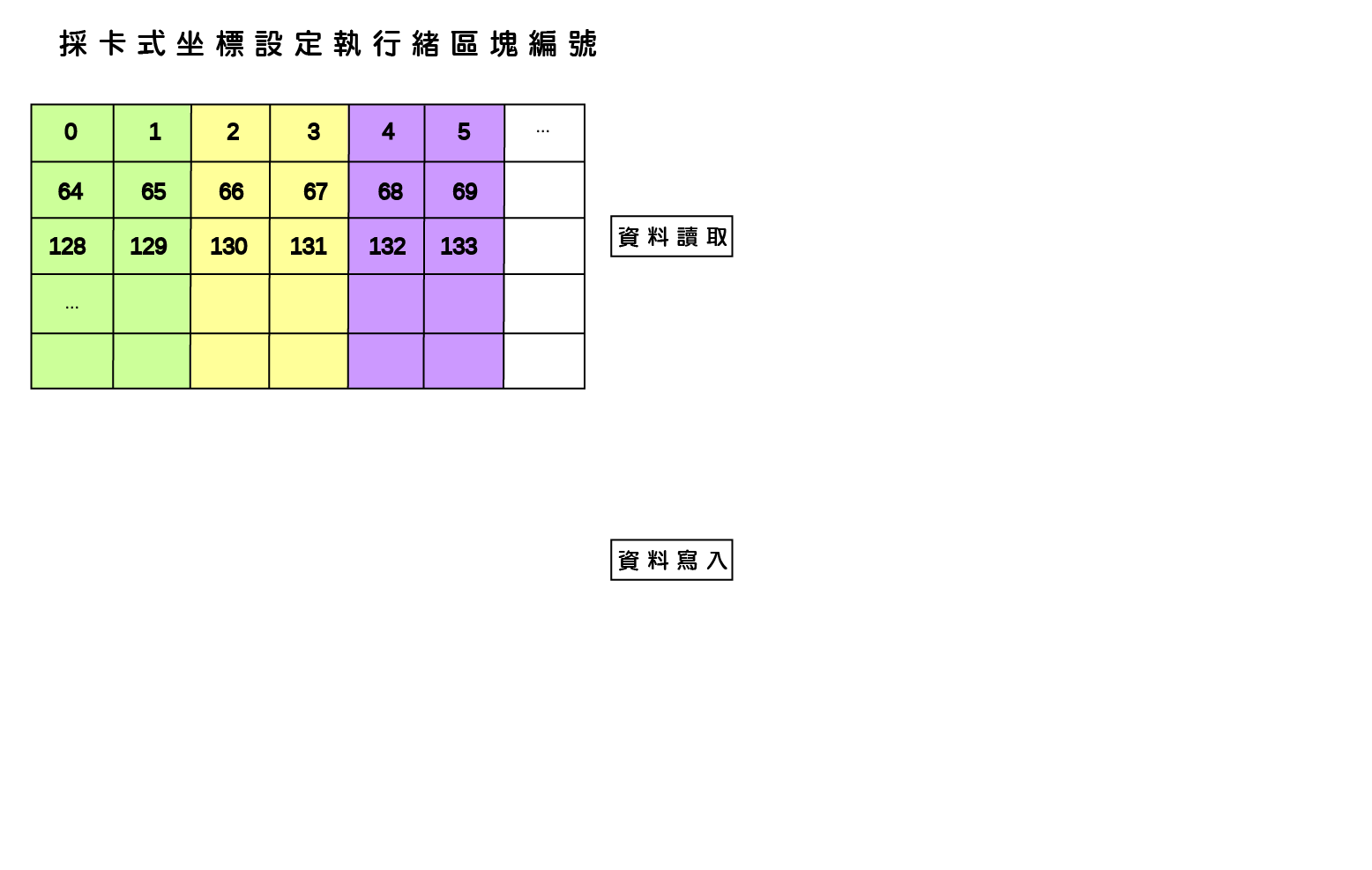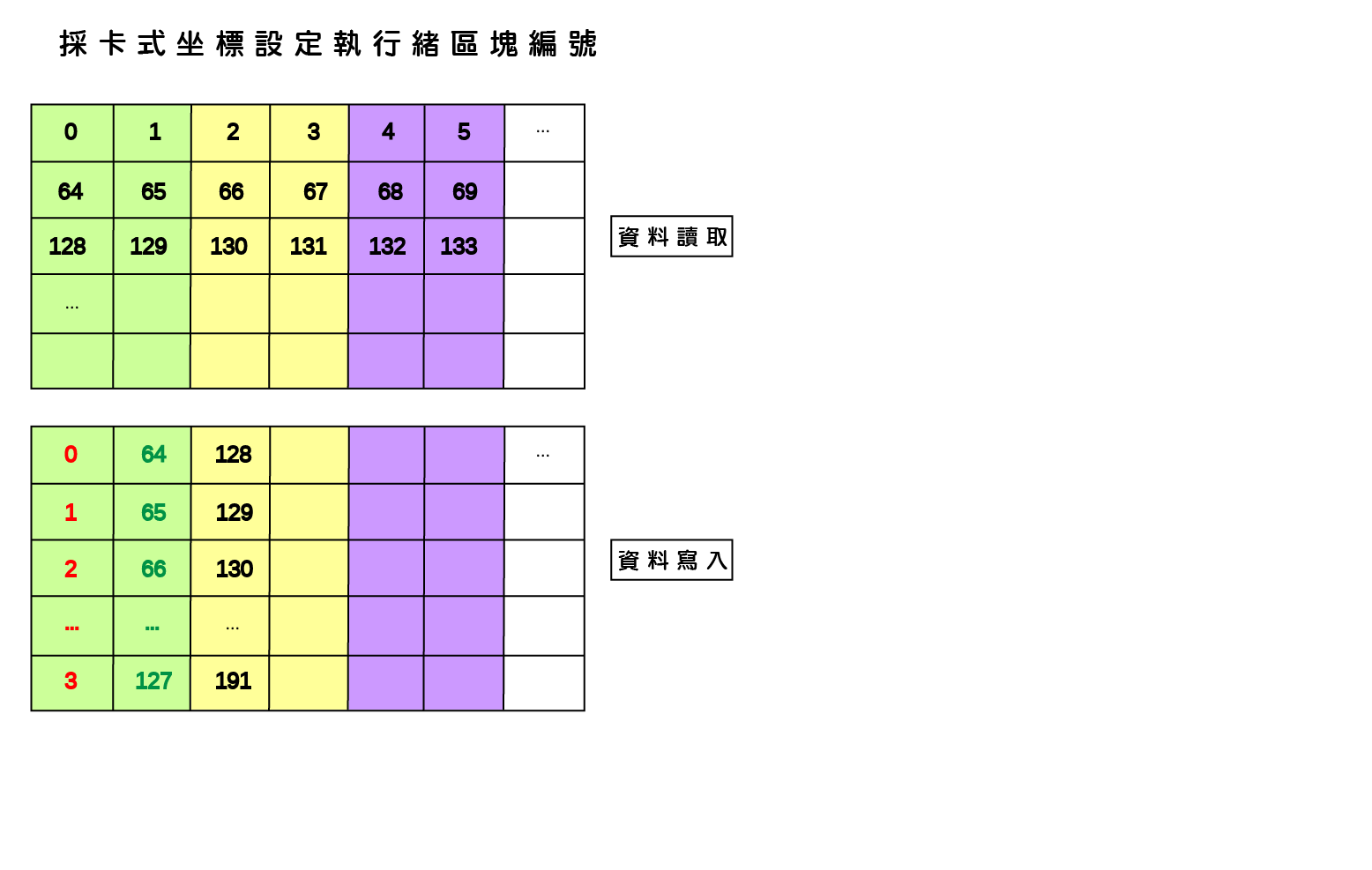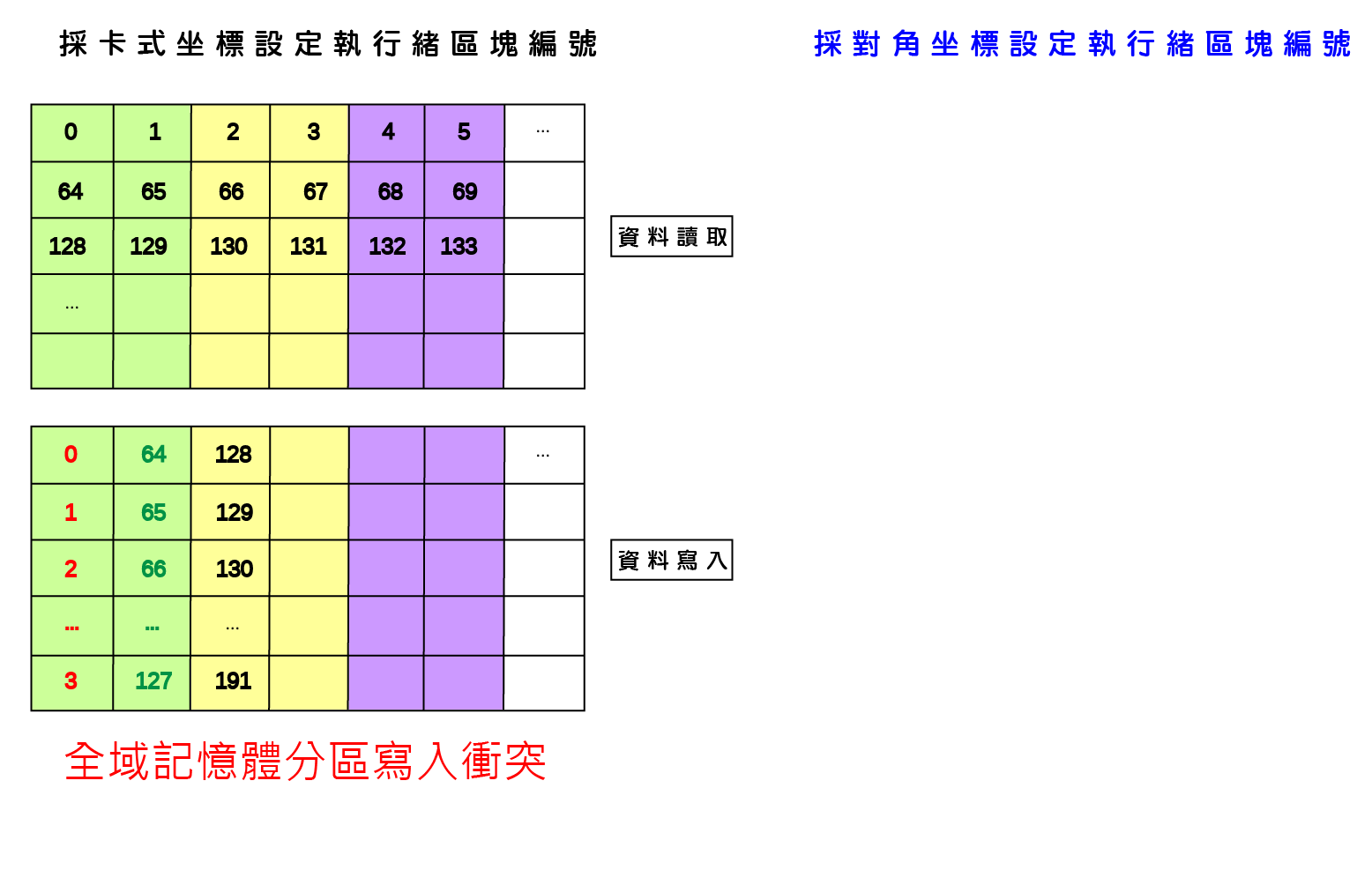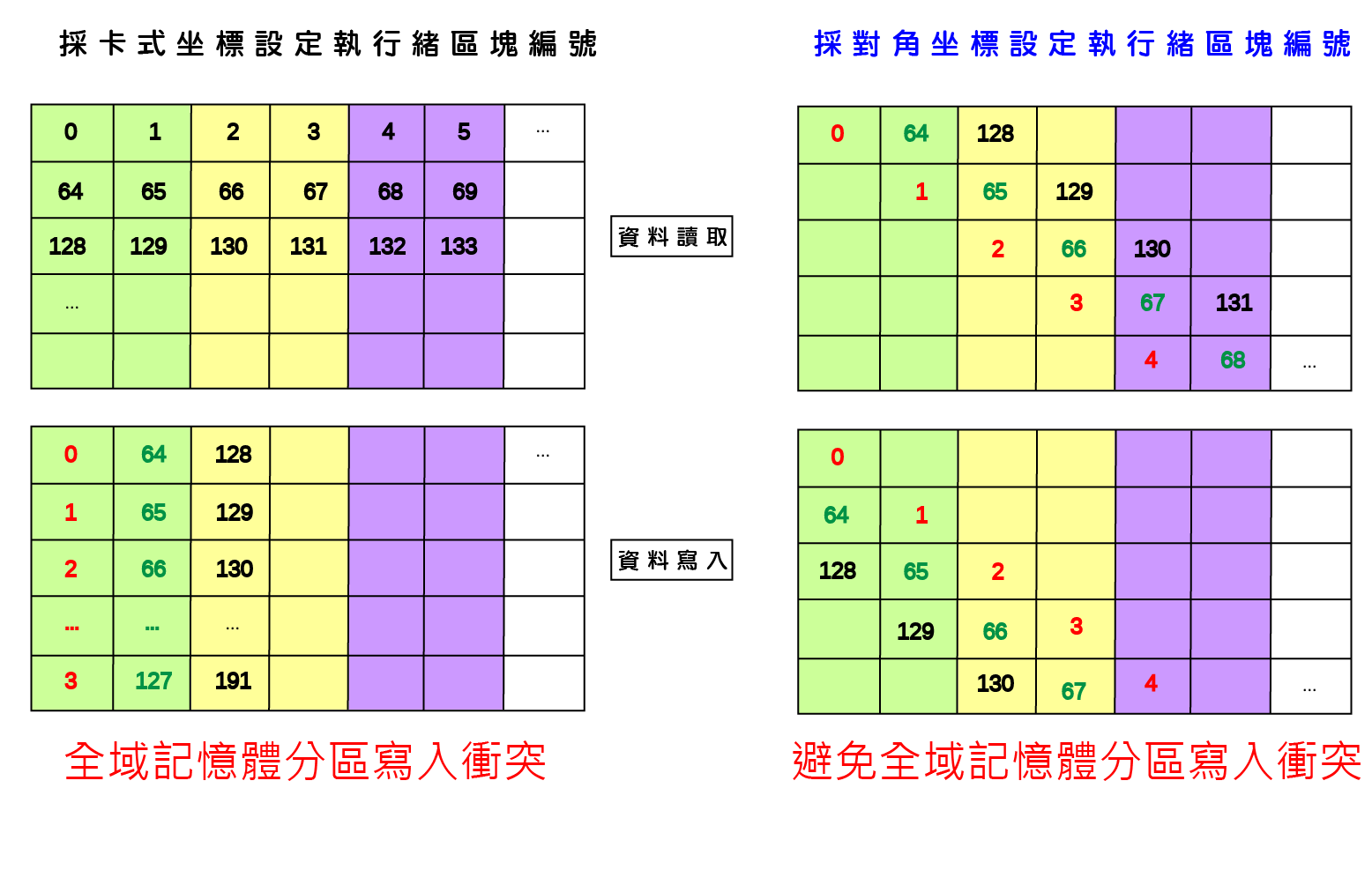
由於GPU記憶體之存取屬性、可視範疇、生命週期與容量大小隨記憶體類型有所不同,並且存取速度具有約100倍的差距,因此GPU應用程式開發需依實際問題特性配置記憶體儲存相關變數,並且避免執行緒讀寫資料可能受到的延遲與限制,才可利用GPU提供之高速計算資源而顯著提升應用程式運算效能。以二維矩陣之複製(copy)以及轉置(transpose)為例,執行緒與執行緒區塊在讀取與寫入記憶體時必須達到『資料合併存取』(Memory coalescing)要求,以及避免發生降低執行效能的共享記憶體『記憶庫衝突』(Bank conflicts)與全域記憶體『記憶體分區寫入衝突』(Partition camping)兩種現象。
GPU記憶體應用關鍵
資料合併存取(Memory Coalescing)

避免共享記憶體<記憶庫衝突>Bank Conflicts
避免全域記憶體<記憶體分區寫入衝突> Partition Camping
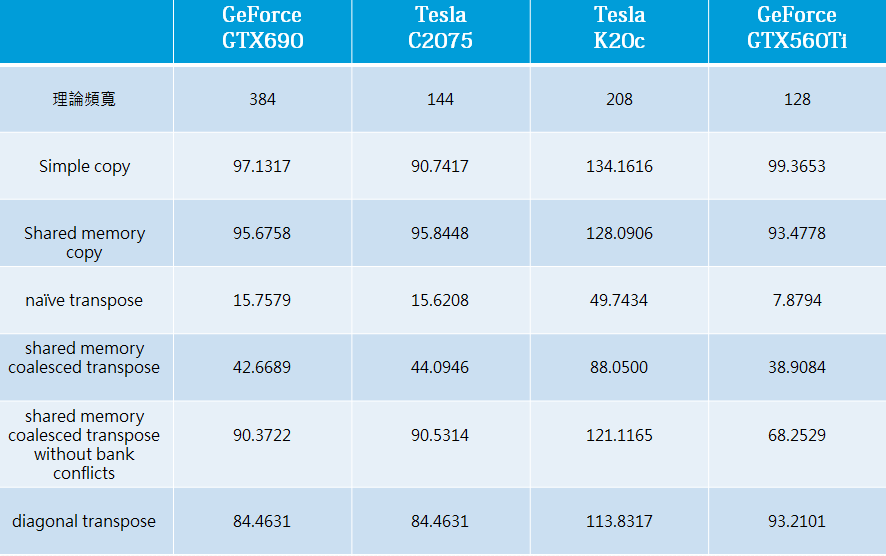
下表所示為2,048×2,048的矩陣進行複製以及轉置時,實作『資料合併存取』(表示為coalesced transpose)並且避免『記憶庫衝突』(表示為without bank conflicts)與『記憶體分區寫入衝突』(表示為diagonal transpoe)對於CUDA Fortran 應用程式於 NVIDIA GeForce系列的GTX 560 Ti與GTX 690以及 Telsa系列的C2075與K20c等圖形處理器上執行時之記憶體實際頻寬差異(越高越好)。各組實驗均設定執行緒區塊大小為64x64x1,每個執行緒區塊內的執行緒為32x8x1。
![]()
硬體對於矩陣複製與轉置實驗記憶體頻寬(GiB/sec)的影響
假設GPU應用程式執行矩陣複製或轉置的運算時間為t秒,則記憶體實際頻寬(effective bandwith)的計算方式為(2,048×2,048x4x2)/(1,0243)/t,其中,4表示矩陣中之各元素為4 位元組(bytes),2代表讀取與寫入兩步驟,除以1,0243則可將位元組換算成GiB。應用程式估計CUDA計算核心實際運作時間可利用CUDA提供的函式cudaEventElapsedTime (time, startEvent, stopEvent)來求得,其中startEvent為事件起始時間,stopEvent為事件結束時間,單位為10-3秒。

